Follow the LinkedIn discussion
My comment
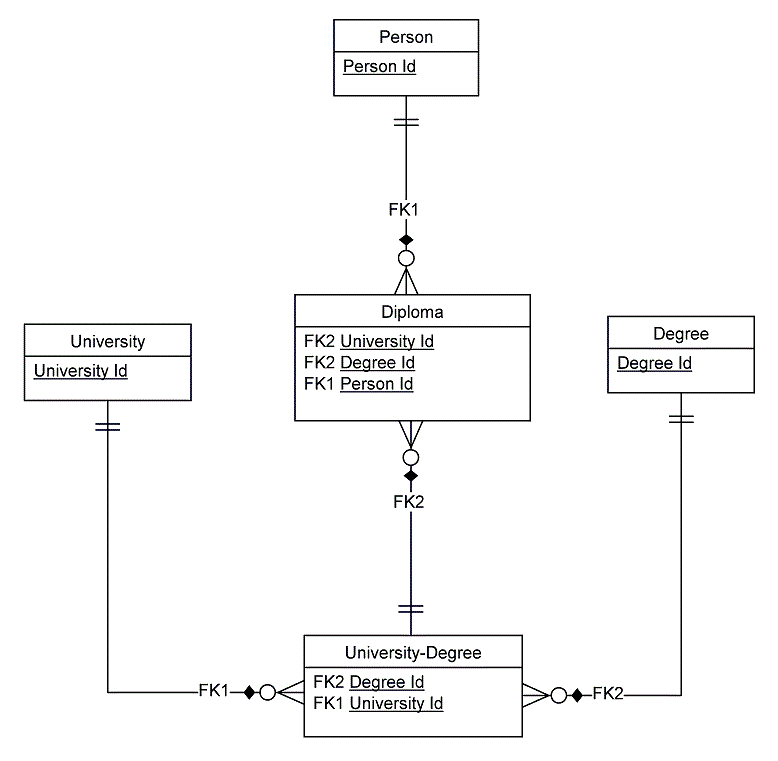
Presuming that many-to-many relationships have been resolved as (binary)
one-to-many relationships, there are two ways to communicate / express
relationships, as
- One-to-many relationships (or optional-one-to-one)
and/or
- Parent-child relationships [Child entity is the side of the relationship where the foreign key (constraint) will be added.]
However, provided that the integrity of the model has been positively
verified, these two ways are synchronized, i.e. the role of the parent
entity and of the child entity in a given one-to-many (or
optional-one-to-mandatory-one) relationship can be derived following the
rule "a mother can have many children, but a child has a maximum of one
mother".
The exception to this rule is an optional-one-to-optional-one
relationship which needs further specification about the parent or child
role of the participating entities.
For this latter case (or an interim state where the integrity of the
model has not been verified yet), an Entity-Relationship diagram in
Information Engineering notation only expresses the multiplicities of a
relationship, but does not offer any "standard" indication about the
parent / child role of an entity in a relationship.
Therefore, I suggest to use a data modeling tool that allows you to e.g.
additionally display the name of the child direction close to the
respective side of the relationship connector.
Once the model is verified and ready to generate foreign keys, the
latter ones will graphically identify the child role of an entity in a
relationship.